Source Code Repository Guidelines
CATS development team is using Git distributed version control system (DVCS) to manage and track source code artifacts. Currently the code is hosted at Github public repository. The common challenge when using DVCS is managing changes and patch from developers to and from a central repository. The team is using the repository found at Github as a central place to push changes to and pull incoming patch.
This guideline is prepared inorder to address the following issues.
- By its distributed nature it is very easy for source code to be out of sync on different developer machines. Since each developer has the exact replica of the central repository we need to put in place good practice to assure changes are replicated on each developer's machine
- To avoid the risk of last minute changes being pushed to the central repository.
- To enforce the practice of Code Freeze
- To define a stable branching and tagging workflow
Git usage
Do commit early and often
Git only takes full responsibility for your data when you commit. If you fail to commit and then do something poorly thought out, you can run into trouble. Additionally, having periodic checkpoints means that you can understand how you broke something. Commit Early And Often. Don't let tomorrow's beauty stop you from performing continuous commits today.
Don't panic
As long as you have committed your work (or in many cases even added it with git add) your work will not be lost for at least two weeks unless you really work at it (run commands that manually purge it).
Don't change published history
Once you git push (or in theory someone pulls from your repo) your changes to the authoritative upstream repository or otherwise make the commits or tags publicly visible, you should ideally consider those commits 'written in stone' for all eternity. If you later find out that you messed up, make new commits that fix the problems (possibly by revert, possibly by patching, etc). Yes, of course git allows you to rewrite public history, but it is problematic for everyone and thus it is just not best practice to do so.
Do make useful commit messages
Creating insightful and descriptive commit messages is one of the best things you can do for others who use the repository. It lets people quickly understand changes without having to read code. When doing history archeology to answer some question, good commit messages likewise become very important. The normal git rule of using the first line to provide a short (50-72 character) summary of the change is also very good. Looking at the output of git log --oneline might help you understand why.
Do keep up to date
This section describes the practice of acquiring changes from fellow developers in the team. It has a relationship with the Git workflow (see below).
- Pulling with
--rebase
Whenever you pull changes from the central repository usegit pull --rebase. This is because it allows you to see linear history (your commit will come after all commits that were pushed before it, instead of being developed in parallel). It makes history visualisation much simpler to see and understand. A specific circumstance in which you should avoid usinggit pull --rebaseis if you merged since your last push. you might want togit fetch; git rebase -p(and check to make sure the merge was recreated properly) or do a normal merge. - Rebasing (when possible)
When you are using a shared repository (such as the case of CATS) with other developers, rebasing is rewriting public history and should/must be avoided. You may only rebase commits that on-one else has seen (which is whygit pull --rebaseis safe). - Merging without speeding
git mergehas the concept of fast-forwarding, or realizing that the code you are trying to merge in is identical to the result of the code after merge. Thus instead of doing work, creating new commits, etc, git simply changes the branch pointers (fast forwards them) and calls it good. This is good when doinggit pullbut not so good when doinggit mergewith upstream branch. The reason this is good is because looses information specifically it loses track of which branch is the first parent and which is not. If you don't ever want to look back into history, then it does not matter. However, if you want to know the branch on which a commit was originally made, using fast-forward makes that question impossible to answer.
Do periodic maintenance
- Validate your repo using
git fsck. - Compact your repo using
git gcandgit gc --aggressive Validate your repo is sane (
git fsck)Prune your remote tracking branches (
git remote | xargs -nl git remote prune). This will get rid of any branches that were deleted upstream since you cloned/pruned. It normally isn't a major problem one way or another, but it might lead to confusion.Check your stash for forgotten work (
git stash list). If you don't do it very often, the context for the stashed work will be forgotten when you finally do stumble on it, creating confusion.
Git workflow
Daily workflow
The daily workflow is what each developer is recommended to follow in his/her day-to-day development effort. While using git you can come up with quite a number of options to define your daily workflow and due to this we need to have a clear and straight forward workflow for every developer to follow. The simple workflow consists of the following steps:
- When you are starting to work on a task/feature/bug begin by pulling the latest source from the repo at github (
git pull origin master) - Create a new branch to represent your feature/issue/bug. (
git checkout -b branch-name-here) - Do your work
- Add any new files you created or modified (
git add . ) - See the changes you are going to commit using git status and git diff (
git status and/or git diff) - Commit very often and keep your commits in small chunks - the smaller your commits the better. Each commit should only represent a single intent, for example implement save action method. Provide a descriptive and detailed message for your commit buy including the issue number from the tracking system. (
git commit -m "CATS-887 Your commit message here") - Make sure that your tests pass and your code builds on your machine
- When your feature is done checkout the master branch to switch to it (
git checkout master) - Merge your feature branch into master to update your changes (
git merge branch-name-here) - Send your changes up to the remote repository. (
git push)
The following diagram illustrates the steps above.
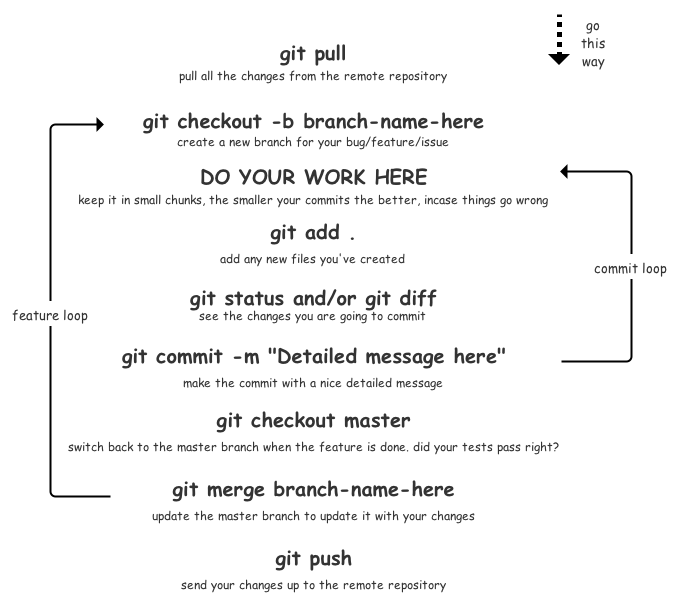
Note: The daily workflow is sometimes referred as "feature branch".
Code Freeze workflow
The code freeze workflow helps the team to have a stable and error-free code base at any single point in time. This is in fact to avoid any surprises during last days of sprints and make sure that there is "potentially shippable product" at the end of each sprint. This is achieved by creating a tagged version on the stable commit two days before the demo.
Release branching
Release branches support preparation of a new production release. They allow for freezing a stable and production ready code and also for minor bug fixes and preparing meta-data for a release (version number, build dates, etc.). The release branching can be applied either at the end of each sprint or for a major release. By doing all of this work on a release branch, the master branch is cleared to receive features for the next release.
The key moment to branch off a new release branch from master is when master (almost) reflects the desired state of the new release. At least all features that are targeted for the release-to-be-built must be merged in to master at this point in time. All features targeted at future releases may not or they must wait until after the release branch is branched off. It is exactly at the start of a release that the upcoming release gets assigned a version number - not any earlier. Up until that moment the master branch reflected changes for the next release/sprint demo.
Creating a release branch
Release branches are created from the master branch. So we branch off and give the release branch a name reflecting the version number. The version number convention in CATS is as follows:
Yared Ayalew Add major releases and sprint demo releases with appropriate versioning
git checkout -b release-1.2 master git commit -a -m "Create branch for R01.2 demo"
After creating a new branch we will only be doing bug fixes and no additional new features will be added. This will assure that the branch will remain stable and no new bugs/issues are introduced due to efforts to add new features. The new branch may exist there for a while, until the release is rolled out. During that time, bug fixes may be applied in this branch (rather than on the master branch). Adding large new features here is strictly prohibited. They must be merged into master, and therefore, wait for the next release (major or sprint).
Finishing a release branch
When the state of the release branch is ready to become a real release, some actions need to be carried out. First the release branch is tagged for easy future reference. Next the changes made on the release branch need to be merged back into master so that future releases/branches also contain these bug fixes.
Yared Ayalew consider improving the release workflow by introducing two infinite branches (master and develop)